要讨论这个问题,首先要了解计算中 GPU 与 CPU 架构的区别及并行的处理方式。
CPU 与 GPU 架构的区别
CPU 和 GPU 在基本架构层面上存在巨大的差异,CPU 有庞大而广泛的指令集,可与更多的计算机组件(例如内存、输入和输出)交互以执行复杂的指令;而 GPU 是一种专门的协处理器,只有在高数据吞吐量的任务上表现出色,而在其他任务上的表现则不尽如人意。

CPU 更强调指定运行的低延迟,其处理方式主要为串行,如果遇到多任务并发需求,则只能通过切换进行,切换时 CPU 必须重置寄存器和状态变量、刷新缓存等等。不过 CPU 经过延迟优化,在多个任务之间的切换速度非常快,让人感觉它在并行处理任务,但本质上,它仍为一次运行一项任务。因此 CPU 可迅速处理各种不同难度的任务,但面对源源不断的重复性任务也会力不从心。因此想要提高 CPU 的性能,需要靠不断提高主频来实现,比如常见的 CPU 主频为 2~4GHz。
相比之下,GPU 更强调高数据吞吐量,其核心的主频通常为 1GHz 左右,提高处理速度除了提高主频和架构,也常常通过“堆料”的方式进行,即增加流处理器的数量。因此相对于 CPU, GPU更适合于重复性和高度并行的计算任务,最常规也是最初始的应用便是图形渲染和显示。后来人们发现它对多组数据执行并行操作的能力,也非常适合于某些非图形任务,例如机器学习、金融模拟、科学计算等大规模且反复运行相同数学函数的活动。
并行处理
并行处理有三个分类:数据并行、指令并行和线程并行。线程是一串串行执行的指令,每条指令操作一个或多个数据。在此基础上,实现并行的方式有三种,一种是多个这样的串行指令序列同时执行,就是 Hydra 为代表的多线程并行模式;第二种数据并行是同一条指令应用在并行的数据上。比如本来是一条加法指令计算 C=A+B,同时将加法应用到一组 A 和一组 B 上得到一组 C 上就是数据并行。这就是典型的单指令多数据 SIMD(Single Instruction Multiple Data)架构。第三种是指令并行,也就是说在同一时间发射多条指令,同时计算不同数据多个不同运算,这是典型的VLIW(Very Long Instruction Word)架构。但是由于实现 VLIW 的编译器难度太高,使得直接实现大规模可扩展的指令并行比较困难。
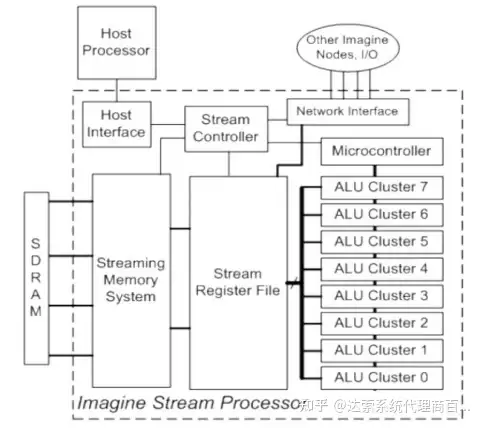
Imagine 是斯坦福的一个数据并行的多核处理器。Imagine 有 8 个 ALU 单元被同一个控制器所控制,同时对大量的并行数据进行同样的操作。这种处理器的模式后来被称为流处理器,也是现今 Nvidia 采用的架构,如 Fermi 系列,就是这种数据并行流处理器的一种实现实例。下图即是Imagine 的结构框图,可以看到它犹如一个大型 SIMD 单元簇。不可否认的是,就这样一个看似简 单的设计架构却能极大地提高数据运算的并行度,使得它在处理 SIMD 数据时,如 FDTD/FITD 这样对同一数据地址上的数进行完全相同的简单 ALU(算术逻辑单元 – Arithmetic Logic Unit)操作具有极高的并行效率。
接下来我们来考察一下 GPU 处理器的结构,如 Nvidia Fermi 系列,不难发现他们和 Imagine 有着惊人的相似之处,即每个处理器核是一个简单的 ALU 阵列。在 Nvidia 的名词里,处理器核叫Streaming Multiprocessor(SM),每个 Fermi 的 SM 里有 32 个 32 位的 ALU、32 个单精度的浮点运算单元还有一些特殊运算单元。SM 相当于 Imagine 中的 ALU Cluster,能够执行 SIMD 的操作,但是绝对和 Intel 以及 AMD 中的处理器核相距甚远。通用处理器中的每个核拥有庞大的指令池 Pool和寄存器堆 Stack,可执行繁杂的指令预取、分支预测、条件跳转等操作,虽然计算单元不如 SM多。换句话说,如果你的程序没有那么宽的单指令多数据并行,就不要指望 SM 比传统处理器核快。
了解了 CPU 和 GPU 的架构后,不难得出如下结论:当程序或算法中存在大量规则数据并行的操作或运算时,GPU 将是最佳选择;相反地,当程序中有大量的分支或跳转或对不同数据源需要进行操作时,CPU 的效率更高。即 SIMD 部分占整个运算的百分比,此百分比越大,则采用 GPU的效果将越好,否则,采用 CPU 会更好。所以并不是一般人所理解的,GPU 就适用于 FDTD,而不适用于 FEM,只是 FEM 中能够进行 SIMD 的部分太小,所以 CPU 对其更有效而已。